

Warum dieser Artikel?
Hintergrund
Ein Trend, welcher sich bereits seit der Veröffentlichung der ersten Llama-KI-Modelle durch Meta Ende 2022 deutlich abgezeichnet hat, erreichte durch die Veröffentlichung der Deepseek KI-Modelle V3 und R1 Ende 2024 erstmals auch den Mainstream und löste ein kleines Beben bei Tech-Anbietern und Investoren aus: Open Source KI-Modelle sind konkurrenzfähig oder sogar leistungsfähiger als jene von sogenannte Closed Source Anbietern wie OpenAI, Google und Co. Doch ist jedes als Open Source beworbene KI-Modell tatsächlich frei und ohne Einschränkungen nutz- und einsehbar?
Mit Blick auf die zunehmenden Governance- und Compliance-Anforderungen z. B. im Rahmend es EU-AI-Acts (KI-Verordnung) oder der DSGVO, ist abzusehen, dass Open Source KI-Modellen eine Schlüsselrolle zukommen wird. Diese ermöglichen (je nach Modell) wirklich transparente, vertrauenswürdige und souveräne KI-Systeme, ohne Abhängigkeiten zu Drittanbietern aus Übersee.
Bedingt durch die lange Zeit fehlende Definition von Open Source KI haben sich unterschiedliche Lizenzierungen, Begrifflichkeiten und Abwandlungen ergeben. Nicht jedes Open Source Modell darf z. B. (uneingeschränkt) kommerziell genutzt werden oder bietet tatsächlich vollständige Transparenz, was den Zugriff auf die Trainingsdaten einschließt. Nicht jedes als Open Source beworbene Modell ist damit auch tatsächlich Open Source.
Mit diesem Artikel möchte ich eine Einordnung und Unterschiede zwischen Open-Source-, Open-Weight- und Closed Source KI-Modellen sowie deren Lizenzmodellen geben.
Inhalt und Aufbau des Artikels
In diesem Artikel möchte ich auf folgende Punkte eingehen:
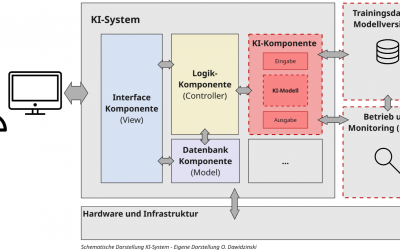
Der Unterschied zwischen KI-Modellen und KI-Systemen
Für viele sind ChatGPT und Modelle wie GPT-4o ein und das selbe. Nämlich KI. Dabei gibt es entscheidende Unterschiede. Bei ChatGPT (und den meisten anderen KI-Anwendungen) handelt es sich um ein KI-System, welches aus vielen verschiedenen Komponenten besteht und im Grund ein Software-System wie Office oder eine App ist. Der Kernteil, welcher aus einem Software-System nun ein KI-System macht, sind die sogenannten KI-Modelle wie GPT-4o. Mit Blick auf generative KI (genAI) sind dies Stand 2025 überwiegend sogenannte Large Language Models (LLMs). Diese sind in der Regel bereits auf großen Text- und Datenmengen sowie mit hohem Ressourcenaufwand von externen Anbietern, Organisationen oder Firmen vortrainierte Algorithmen und neuronale Netze. Die für diesen Trainingsprozess und das daraus entstehende Modell relevanten Komponenten sind dabei die Trainingsdaten, das oder die Trainingsverfahren und (Hyper-) Parameter, die Modell-Architektur, die nach dem Training erzeugten Modell-Gewichte und der Code zur Ausführung des Modells.
Über die Begriffe „Closed Source„, „Open Source“ und „Open Weight„, wird im Grund beschrieben, wie groß der Grad an Transparenz, Nutz- und Prüfbarkeit der jeweiligen Modelle aussieht. Das betrifft in der Regel auch die Nutzungsrechte, Lizenzen und erweiterte Definitionen. Diese Definitionen möchte ich folgend etwas näher erklären.
Was sind Closed Source-Modelle?
Closed Source-Modelle, auch als proprietäre KI-Modelle bezeichnet, sind solche, bei denen in der Regel der Zugriff auf die Schlüsselkomponenten des Modells – einschließlich der Trainingsdaten des Trainingscodes und Verfahren, der Modellarchitektur sowie der Modellgewichte bzw. (Hyper-) Parameter – nicht möglich oder stark eingeschränkt ist. Anbieter wie OpenAI (z. B. GPT-4o) oder Google (z. B. Gemini) stellen solche Modelle für gewöhnlich nur über API-Schnittstellen zur Verfügung (API-as-a-Service), ohne Einblick in die “Blackbox” dahinter zu gewähren. Die Nutzung der KI-Modelle erfolgt damit über ein Abo-Modell oder Pay-per-Use im Rahmen der AGBs und Lizenzbedingungen der jeweiligen Anbieter.
Was sind Open Source-Modelle?
Der Gegenpart zu Closed Source sind die Open Source-Modelle. Für diese gibt es nun seit Ende 2024 auch eine offizielle Definition der Open Source Inititaive (OSI). Diese definiert Open Source KI und Modelle dabei wie folgt:
What is Open Source AI
When we refer to a “system,” we are speaking both broadly about a fully functional structure and its discrete structural elements. To be considered Open Source, the requirements are the same, whether applied to a system, a model, weights and parameters, or other structural elements.
An Open Source AI is an AI system made available under terms and in a way that grant the freedoms1 to:
Use the system for any purpose and without having to ask for permission.
Study how the system works and inspect its components.
Modify the system for any purpose, including to change its output.
Share the system for others to use with or without modifications, for any purpose.
These freedoms apply both to a fully functional system and to discrete elements of a system. A precondition to exercising these freedoms is to have access to the preferred form to make modifications to the system.
Open Source models and Open Source weightsFor machine learning systems,
An AI model consists of the model architecture, model parameters (including weights) and inference code for running the model.
AI weights are the set of learned parameters that overlay the model architecture to produce an output from a given input.
The preferred form to make modifications to machine learning systems also applies to these individual components. “Open Source models” and “Open Source weights” must include the data information and code used to derive those parameters.
Quelle (abgerufen am 04.05.2025): https://opensource.org/ai/open-source-ai-definition
Auf unsere KI-Modelle übertragen bedeutet dies, dass ein Open Source KI-Modell die Möglichkeiten bieten muss, sowohl die Trainingsdaten, Trainingsprozesse, Architektur, Code und Gewichte bzw. die (Hyper-) Parameter frei einsehen und nachvollziehen zu können. Dies bedeutet auch, dass die Verwendung, Anpassung und Rekonstruktion ohne Einschränkungen möglich sein muss. Ein wirkliches Open Source Modell wäre damit vollständig transparent, reproduzier– und ohne Einschränkungen nutz- und verwertbar. Das dies aktuell nur auf die wenigsten Modelle zutrifft, wird bei der Definition von Open Weight-Modellen deutlich.
Was sind Open Weight-Modelle?
Anders als bei Open Source Modellen sind bei Open Weight Modellen in der Regel nur die Gewichte bzw. Parameter, welche während des Trainings gelernt wurden, die Architektur oder der Ausführungscode nutz- und nachvollziehbar. Die verwendeten Trainingsdaten werden nicht zur Verfügung gestellt oder öffentlich gemacht. Häufig werden auch die genauen Trainingsmethoden oder Frameworks nicht erwähnt.
Die Modelle (bzw. Gewichte) können damit nicht reproduziert werden und ermöglichen keine vollständige Transparenz. Dies kann tatsächlich ganz direkte Implikationen auf Compliance- und Governance-Anforderungen haben. So kann man als Nutzer z. B. nicht selbst nachweisen, dass für oder während des Trainings keine Copy-Right-Verletzungen oder personenbezogenen Daten verwendet wurden. Genauso kann meist nur durch Reverse-Engineering oder intensive Test- und Evaluierungszyklen sichergestellt werden, dass Anforderungen an Fairness, Bias und Sicherheit auch tatsächlich eingehalten wurden. Beim Rest muss man den Aussagen der Entwickler des Modells vertrauen.
Open Source Lizenzen und kommerzielle Nutzung
Während bei einem nach OSI definierten Open Source Modell keine Einschränkungen bei der Nutzung von Modellen bestehen dürfen, haben insbesondere viele der aktuellen Open Weight-Modelle von Anbietern zusätzlich deutlich restriktivere Lizenzen und Einschränkungen bekommen. Die Llama-Modelle von Meta stehen z. B. unter der Meta Llama Community Licence, welche die Nutzungsbedingungen regeln und Einschränkungen für die kommerzielle Nutzung festlegen. So dürfen für die kommerzielle Nutzung z. B. bestimmte monatliche Nutzerkontingente nicht überschritten werden.
Ähnlich verfährt auch das französische KI-Start-Up Mistral AI, welches zunehmend Modelle unter eigenen Lizenzen veröffentlich, die ausschließlich nicht-kommerzielle Nutzung erlauben, etwa die MNPL-Lizenz (Mistral AI Non-Production License). Diese richtet sich primär an Forschende oder Entwickler, die KI-Systeme testen oder prototypisch einsetzen möchten, ohne sie in profitierende Produkte zu integrieren.
In der Regel ist man bei KI-Modellen (unabhängig ob wirklich Open Source oder “nur” Open Weight) immer auf der sicheren Seite, wenn diese unter einer MIT- oder Apache 2.0 Lizenz veröffentlich wurden.
Fazit: Die meisten aktuell verfügbaren Modelle sind Open Weight und nicht Open Source
Obwohl in der aktuellen Berichterstattung und Kommunikation nach wie vor häufig von Open Source-KI oder Modellen gesprochen wird, handelt es sich bei den genutzten Modellen jedoch überwiegend um Open Weight-Modelle, bei welchen insbesondere die Trainingsdaten fehlen. Für viele (aktuelle) Anwendungsfälle muss dies in der Praxis auch kein Problem darstellen. Die meisten Modelle können auch ohne Probleme (gemäß Lizenz) kommerziell verwendet werden.
Mit Blick auf die im EU-AI-Act definierten Rollen des KI-Lifecycles sowie Risikostufen und damit verbundenen Governance- und Compliance-Anforderungen können Open Weight-Modelle jedoch insbesondere bei KI-Systemen im Hochrisiko-Bereich zu Herausforderungen führen. So gelten z. B. für KI-Systeme der Hochrisiko-Kategorie und GPAI (General Purpose AI) mit systemischem Risiko strickte Dokumentations- und Nachweispflichten, was die Trainingsdaten und Maßnahmen im Kontext Sicherheit, Transparenz und Fairness anbelangt. Ein solcher Nachweis ist bei Nutzung von Open Weight-Modellen ohne Zugriff auf die Trainingsdaten (aktuell) schwer zu erbringen.
Dies betrifft jedoch genau so alle proprietären Anbieter von Closed Source-Modellen wie OpenAI, Google und Co. und könnte auch erklären, warum z. B. OpenAI überraschend zurück zu seinen Open Source-Wurzeln möchte und plant ein “Open Source” Modell zu entwickeln und zu veröffentlichen. Wie weit dieses tatsächlich der Open Source Definition nach OSI entsprechen oder ebenfalls eher in Richtung Open Weight gehen wird, bleibt abzuwarten.

0 Kommentare