
Warum dieser Artikel?
Einleitung
Künstliche Intelligenz (KI) ist längst keine Zukunftsvision mehr, sondern bereits ein integraler Bestandteil unseres Alltags – von intelligenten Assistenten und Prognosemodellen bis hin zu (teil-) automatisierten Workflows und Prozessen. Mit der zunehmenden Verbreitung von KI-Systemen wachsen jedoch auch die Fragen nach ihrer Vertrauenswürdigkeit. Dank der aktuellen Entwicklungen war es nie einfacher, KI-Anwendungen und -Systeme zu bauen oder in Betrieb zu nehmen. Doch erfüllen diese auch im laufenden Betrieb zuverlässig die Anforderungen aus dem Proof-of-Concept und funktionieren transparent, sicher und ethisch einwandfrei?
Der EU-AI Act (die KI-VO) adressiert genau diese Problematik und verlangt, dass Unternehmen und Organisationen nicht nur die technische Funktionalität, sondern auch die rechtlichen und ethischen Implikationen ihrer KI-Anwendungen berücksichtigen (je nach Risikoklasse) – und das über den gesamten KI-Lebenszyklus hinweg, von der Planung und Entwicklung über den Einsatz bis zur Wartung und Außerbetriebnahme.
Das Ziel: Vertrauenswürdige und verantwortungsvolle KI-Systeme.
Doch was kann man darunter verstehen und was ist der Unterschied zwischen vertrauenswürdigen und verantwortungsvollen KI-Systemen?
Letztes Update am 04.08.2025
Inhalt und Aufbau des Artikels
In diesem Artikel möchte ich auf folgende Punkte eingehen:
Was ist vertrauenswürdige und verantwortungsvolle KI?
Vertrauenswürdige und verantwortungsvolle KI kann man im Grunde als ein System oder Anwendung definieren, welche je nach Einsatzzweck und Umgebung so viele KI-bezogene Risiken wie möglich adressiert oder berücksichtigt. Vertrauenswürdige und verantwortungsvolle KI-Systeme zielen damit darauf ab, dass diese sicher und mit angemessenem/vertretbaren Risiko genutzt werden können. Dies bedeutet, dass im Kern solcher Systeme die Ermittlung, Behandlung und Reduzierung von Risiken stehen und damit dem Risikomanagement eine entscheidende Rolle zukommt.
Die KI-bezogenen Risiken können dabei extrem vielfältig sein, lassen sich jedoch grob auf die folgenden Themenschwerpunkte bzw. Risikokategorien verteilen:
- Menschliche Kontrolle und Aufsicht
- Nachvollziehbarkeit und Transparenz
- Verlässlichkeit, Qualität und technische Sicherheit
- Fairness, Bias und Diversität
- Ethik, Umwelt und Einfluss auf die Gesellschaft
- Datenschutz, Informationssicherheit, Geheimschutz
- Betrieb, Verantwortung und (menschliche) Kontrolle
- Einhaltung von Gesetzen, Compliance und Urheberrecht
Die Risikokategorien und einzelnen Risiken lassen sich umgekehrt auch als Anforderungen lesen, welche ein KI-System erfüllen oder berücksichtigen muss. Dabei sind nicht alle zwingend gesetzlich vorgeschrieben. Der EU-AI-Act kategorisiert KI-Systeme in verschiedene Risikostufen sowie Anbieter in verschiedene Kategorien. Je nach Risikostufe, in welche ein KI-System fällt, sind die gesetzlichen Anforderungen und damit auch die Maßnahmen zur Sicherstellung und Behandlung von KI-Risiken umfangreicher.
Zusammenfassend kann man sagen, dass vertrauenswürdige und verantwortungsvolle KI sicherstellt, dass die im jeweiligen Anwendungsfall relevanten Risiken und Anforderungen erfüllt und damit eine sichere und verantwortungsvolle Nutzung möglich ist.
Doch was ist der Unterschied zwischen vertrauenswürdiger und verantwortungsvoller KI und gibt es überhaupt einen?
Was ist der Unterschied zwischen vertrauenswürdiger KI und verantwortungsvoller KI?
Tatsächlich haben sowohl vertrauenswürdige als auch verantwortungsvolle KI grundsätzlich die gleichen Inhalte und werden vielfach synonym verwendet. Der Unterschied liegt damit eher in der Umsetzung der grundlegenden Prinzipien/Anforderungen und den ausführenden Akteuren. So unterscheide ich vertrauenswürdige und verantwortungsvolle KI wie folgt:
Verantwortungsvolle KI (Responsible AI) bezieht sich primär auf die Planung, Konzeption und Entwicklung eines KI-Systems. Eine verantwortungsvolle KI berücksichtigt und erfüllt technisch alle genannten und relevanten Anforderungen, bzw. alle Punkte wurden während der Entwicklung berücksichtigt und adressiert. Ähnlich wie ein Auto, bei welchem sich die Ingenieure im Vorfeld Gedanken gemacht haben, welche sicherheitsrelevanten Funktionen und Anforderungen das Auto am Ende haben oder erfüllen muss und welches von Werk aus mit allen notwendigen Assistenzsystemen ausgestattet ausgeliefert wird. Die Entwickler und Anbieter sind damit ihrer „Verantwortung“ nachgekommen, ein sicheres und vertrauenswürdiges KI-System (oder Auto) zu entwickeln und bereitzustellen.
Die Vertrauenswürdigkeit einer KI (Trusted AI) bezieht sich auf die technische Umsetzung und tatsächliche Praxistauglichkeit. Sie beschreibt wie „gut“ und „sicher“ das KI-System in der Praxis wirklich ist. So kann während der Entwicklung die Gefahr oder das Risiko eines Auffahrunfalls erkannt und in Form eines Airbags berücksichtigt worden sein, wenn dieser jedoch bei einem Unfall nicht auslöst, dann ist das Auto nicht unbedingt vertrauenswürdig, auch wenn die Ingenieure ihrer Verantwortung augenscheinlich nachgekommen sind.
Ein vertrauenswürdiges und verantwortungsvolles KI-System ist damit das Ergebnis einer verantwortungsvollen Planung und Entwicklung sowie einer geprüften Praxistauglichkeit und Funktionsfähigkeit im (laufenden) Betrieb.
Der Unterschied zwischen KI-Modell, KI-System und KI-Architektur
Um ein Bild davon zu bekommen, welche Implikationen vertrauenswürdige und verantwortungsvolle KI-Systeme nun in der Praxis haben können, ist es wichtig zu verstehen, was ein KI-System eigentlich ist und ausmacht. In den Medien, Nachrichten und bei Produktbeschreibungen wird in der Regel nur von KI oder KI-Anwendungen gesprochen. Tatsächlich handelt es sich aber, abseits von theoretischen Konstrukten oder den reinen Modellen (dazu gleich mehr), eigentlich immer um KI-Systeme. Ein KI-System ist ein Zusammenspiel aus einer Vielzahl unterschiedlicher Komponenten und im Grunde erst einmal nichts weiter als Software, wie eine App auf dem Handy, ein Office-Programm oder ein Browser.
Sie alle benötigen oder bestehen überwiegend aus Komponenten wie einer Datenbank, einem Interface (GUI) zur Interaktion, Programmlogik, einer Architektur, welche das Zusammenspiel regelt, und Infrastruktur bzw. Hardware, auf welcher die Software läuft. Wenn wir dies auf unser Beispiel mit dem Auto übertragen, dann wäre das fertige Auto unser KI-System. Dabei besteht das Auto ebenfalls aus verschiedenen Komponenten. Das Chassis entspräche der Architektur, die Räder der Infrastruktur, das Lenkrad, Infotainment-System sowie die Bedienelemente dem Interface und das Getriebe sowie den Boardcomputer kann man sich als Programmlogik vorstellen.
Der Teil, welcher nun aus einem Softwaresystem ein KI-System macht, ist die KI-Komponente. Diese besteht in der Regel aus einer vordefinierten Ein- und Ausgabe-Schnittstelle (Pipeline), deren Kern das sogenannte KI-Modell bildet. Beim KI-Modell handelt es sich (vereinfacht gesagt) um das persistierte Ergebnis eines ausgewählten Machine-Learning-Prozesses. Mit diesem wurde auf Basis von Trainingsdaten ein geeigneter Algorithmus zur Erreichung unterschiedlicher Zielsetzungen oder Ausgaben trainiert. Dieser trainierte Algorithmus bildet das KI-Modell. Er erwartet in der Regel fixe Eingabeformate und kann auch nur solche Ausgaben oder Ausgabeformate generieren, welche im Trainingsprozess bzw. bei der Erstellung des Modells vorgegeben wurden. Wenn wir wieder an unser Auto denken, dann würde das KI-Modell dem Motor entsprechen. Ein Motor würde als Eingabe ebenfalls nur bestimmte Treibstoffe erwarten und seine Leistung ist konstruktionsbedingt vorher definiert und spezifiziert.
Das KI-Modell bzw. die KI-Komponente ist damit (als Motor) der entscheidende Teil eines KI-Systems. Wenn wir aktuell mit ChatGPT interagieren oder Copilot nutzen, dann interagieren wir mit einem KI-System und nicht mit dem eigentlichen KI-Modell. Dabei haben wir die Möglichkeit, auch direkt mit dem KI-Modell zu interagieren oder dies zu nutzen. So stellt OpenAI z. B. Zugriff auf alle seine KI-Modelle, welche auch als KI-Komponente hinter seinen Anwendungen wie ChatGPT etc. stehen, über eine API bereit.

Damit ist es praktisch für jede Person mit ausreichend Softwareentwicklungskenntnissen möglich, eigene KI-Systeme zu entwickeln. Wo früher aufwendige und kostspielige Trainings- und Entwicklungsphasen für eigene KI-Modelle notwendig waren (welche dann auch nicht universell eingesetzt werden konnten), kann man heute mit wenig Aufwand auf die leistungsfähigsten KI-Modelle zugreifen, diese beliebig einsetzen und integrieren. Dies ist übrigens auch einer der (möglichen) Gründe für die aktuelle Flut an KI-Start-ups und -Anwendungen. Die wenigsten entwickeln wirklich eigene KI-Komponenten oder Modelle, sondern integrieren einfach die bestehenden KI-Modelle oder Komponenten von Anbietern wie OpenAI, Google oder Anthropic über APIs in ihre Software oder bauen diese darum herum auf.
Diese Entwicklung lässt sich (entfernt) ebenfalls wieder auf unser Autobeispiel anwenden: Für premium Autohersteller war lange Zeit der Verbrennungsmotor ein Alleinstellungsmerkmal, da es für andere Unternehmen extrem schwierig war, vergleichbar effiziente und leistungsfähige Motoren zu entwickeln. So gab es auch wenige neue Automobilhersteller. Mit der Elektromobilität hat sich dies geändert. Da Elektromotoren deutlich weniger komplex und anspruchsvoll in der Entwicklung sind, haben sich in kürzester Zeit neue Konkurrenten erfolgreich etabliert, welche „fertige“ Elektromotoren in ihre individuellen Chassis einbauen und damit eigene Autos anbieten können.
Die Bedeutung von KI-Modell und KI-System für vertrauenswürdige und verantwortungsvolle KI in der Praxis
Wie eingangs eingeleitet, hat die Unterscheidung von KI-Systemen und KI-Modellen jedoch insbesondere für vertrauensvolle und verantwortungsvolle KI-Systeme eine große Bedeutung und dazu muss ich etwas tiefer in die Funktionsweise von Machine Learning und deren Funktionsweise einsteigen:
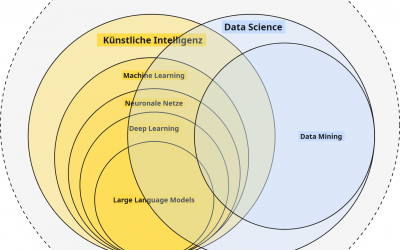
Wer Hintergründe zu Data Science, ML und KI sucht, mag vielleicht einen Blick in diese Beitrag von mir werfen: https://dawidzins-ki.de/ki-kompetenz-teil-2-der-unterschied-zwischen-ki-data-science-und-co/)
Eine charakteristische Eigenschaft von KI-Modellen ist, dass diese tatsächlich nur so gut sind wie die Daten, mit welchen sie trainiert wurden (ja, ja, Daten sind das neue Gold…). Wenn jedoch in den Daten gewisse Abweichungen oder Verzerrungen existieren (z. B. wenn in den Trainingsdaten zur Vorhersage von Preisen von Autos keine E-Autos dabei waren), dann wird ein Modell oder KI-System, welches dieses Modell integriert, keine (korrekten) Vorhersagen für z. B. E-Autos machen können. Deutlich schlimmer wird es bei Personengruppen, Sprachen oder Entitäten (z. B. konnten deshalb früher viele Open Source LLMs kein Deutsch, weil in den Trainingsdaten kaum deutsche Texte waren). Das Gleiche gilt für Änderungen in den Datenverteilungen. So können sich die Verteilungen von Geschlechtern zur Prognose einer Schadensfreiheitsklasse im Laufe der Jahre ändern und von der abweichen, welche während des Trainingsprozesses in den Trainingsdaten abgebildet und vom KI-Modell gelernt wurde. Das KI-Modell würde damit falsche Prognosen erzeugen.
Aus Sicht von vertrauenswürdiger und verantwortungsvoller KI ist es deshalb entscheidend, dass die KI-Komponente in einem KI-System überwacht wird und Wissen über die Trainingsdaten, Verfahren und dessen Performance vorhanden ist. Insbesondere der (kontinuierliche) Abgleich der Performance aus dem Training mit aktuellen Leistungsdaten ist essenziell wichtig, um ggf. Abweichungen in der Qualität und Genauigkeit der Ausgaben eines KI-Modells zu erkennen. Man spricht bei solchen Konzepten dann von Modell- oder Konzept-Drifts.
Ein weiteres und aktuelles Beispiel ist der Datenschutz und Urheberrecht. Die DSGVO verlangt z. B., dass Nutzer jederzeit von Anbietern verlangen können, dass ihre personenbezogenen Daten gelöscht werden. Wenn nun in einem aktuellen generativen KI-Modell, wie z. B. einem hinter ChatGPT, personenbezogene Daten im Trainingsdatensatz vorhanden waren, dann hat das Modell diese gelernt und diese Informationen können in der Regel nicht ohne Weiteres aus einem Modell wieder entfernt werden, ohne das Modell ggf. zu beschädigen. Das Gleiche gilt für die Sicherstellung, dass KI-Systeme nicht für schädliche oder verbotene Handlungen genutzt werden.
Um dies zu verhindern bzw. sicherzustellen, werden vor oder nach einem KI-Modell oder einer KI-Komponente Filter- oder Moderations-Ebenen eingeführt. Schädliche Anfragen oder Ausgaben werden damit nach der Erzeugung, aber vor der Übertragung an einen Nutzer gefiltert oder verhindert. Damit kommen wir zu der Bedeutung und dem Zusammenhang von KI-System, einzelnen Komponenten und vertrauenswürdiger und verantwortungsvoller KI. Jede der Komponenten in einem KI-System ist in der Regel ein mögliches Risiko bzw. ein Faktor für die Sicherheit und Vertrauenswürdigkeit eines KI-Systems. So kann z. B. bereits über das Interface einer Chat-Anwendung die Eingabe von Code verhindert werden und damit Prompt-Injections bereits in der Interface-Komponente abgefangen werden. Genauso wäre es aber auch möglich, dass ein Hacker durch schlechte Sicherheitsmaßnahmen Zugriff auf die Anwendung erhält, diese manipuliert oder ganz abschaltet.

Man sieht, dass sowohl für die Planung und Entwicklung, aber auch für den Betrieb und Einsatz von vertrauenswürdiger und verantwortungsvoller KI ein tiefergehendes Verständnis über den Aufbau und den Unterschied zwischen einem KI-System, KI-Modell und der beteiligten Komponenten vorhanden sein sollte.
Fazit
Auch wenn aktuell das Thema der vertrauenswürdigen und verantwortungsvollen KI durch den AI Act und andere Regulierungen sehr prominent ist, so ist das Konzept dahinter nicht neu. Im Grunde war es für jeden Entwickler oder Nutzer eine Grundvoraussetzung, dass ihre KI-Modelle und -Systeme im Rahmen der jeweiligen Problemstellung vertrauenswürdig und verantwortungsvoll funktionieren, da es sich in der Regel immer um Individualentwicklungen und eigene Modelle handelte, deren Entwicklung und Betrieb mit hohen Kosten verbunden war. Die Einhaltung der Anforderungen an vertrauenswürdige und verantwortungsvolle KI war damit in der Regel alleine aus Qualitäts- und Kostengründen im eigenen Interesse (vgl. MLOps). Doch waren solche Systeme meist nur für sehr begrenzte Aufgaben und Nutzergruppen bestimmt und ihr Einsatz und Betrieb darauf abgestimmt.
Aktuelle generative KI-Modelle sind generalistisch, für eine Vielzahl an Anwendungsfällen geeignet und vor allem können sie, wie bereits erwähnt, von so gut wie jedem Entwickler oder auch Endnutzer bedient und eingesetzt werden. Die dadurch entstehende Flut an neuen KI-Systemen und Produkten, sowie die deutlich größere Nutzerschaft und Risiken, rücken die Konzepte der vertrauenswürdigen und verantwortungsvollen KI wieder in den Fokus.
Diese Problematik versucht der EU AI Act nun einen Rahmen zu geben und durch seinen risikobasierten Ansatz zu adressieren. Meiner Meinung nach ist dies der richtige Weg, auch wenn die damit verbundenen Dokumentations- und Organisationsmaßnahmen sicherlich (mal wieder) weit über das Ziel hinausgehen. Ich vertrete die Ansicht, dass KI-Systeme alleine aus den bereits angesprochenen Qualitätsgründen und zur laufenden Sicherung dieser, vertrauenswürdig und verantwortungsvoll sein sollten und dies über den gesamten Lebenszyklus hinweg. Wo bei klassischen deskriptiven KI-Modellen während der Trainings- und Evaluierungsphasen aufwendig getestet wurde, ersetzen heute wenige Prompts den Trainingsprozess, werden auf zu wenig Daten im Vorfeld getestet und im laufenden Betrieb nur unzureichend überprüft. Meiner Meinung nach ist dies auch einer der Gründe, warum vielfach das Gefühl umgeht, dass 80 % der erfolgreichen Proof-of-Concepts spätestens in Produktion scheitern. Prozesse und Techniken im Rahmen von MLOps oder AI-Management-Systemen würden damit nicht nur die Einhaltung von Compliance und Governance-Anforderungen bedeuten, sondern ganz praktisch die Funktionsfähigkeit und damit Qualität sicherstellen.
Vertrauenswürdige und verantwortungsvolle KI und deren Berücksichtigung sowie Umsetzung bedeutet damit für mich nicht nur weitere regulatorische Anforderungen im Rahmen von KI-Compliance und Governance, sondern stellt als zentrales Konzept die Qualität und Leistungsfähigkeit von KI-Systemen sicher.

0 Kommentare