
Warum dieser Artikel?
Einleitung
Durch AI-as-a-Service-Anbieter wie OpenAI, Google oder Anthropic war es noch nie so einfach, Zugang zu KI-Modellen zu bekommen und diese in eigene Anwendungen zu integrieren. Über einheitliche Schnittstellen, sogenannte APIs, bieten OpenAI, Google und Co. jedem die Möglichkeit, ihre KI-Modelle in eigene KI-Anwendungen zu integrieren oder neue zu entwickeln.
Was auf den ersten Blick wie eine großartige Entwicklung klingt, birgt in der Praxis viele Risiken und Probleme, denn für produktive KI-Anwendungen wie ChatGPT, Copilot oder Gemini sowie Hochrisiko- und regulierte KI-Anwendungen braucht es weit mehr. Vertrauenswürdige und verantwortungsvolle KI-Anwendungen müssen Anforderungen an Funktionalität (Qualität) und Sicherheit, Konformität (z. B. EU AI Act), User Experience sowie Rentabilität erfüllen. Aus diesem Grund handelt es sich bei solchen Anwendungen in der Praxis um komplexe KI-Systeme, die aus einer Vielzahl von Komponenten bestehen, von denen das KI-Modell nur eine von vielen ist.
In diesem Beitrag möchte ich einen Überblick geben, welche (technischen) Komponenten ein vertrauenswürdiges und verantwortungsvolles (GenAI) KI-System umfassen sollte und warum. Ich beschreibe diese dabei aus der technischen Sicht eines AI-Solution-Architects. Die Komponentenstruktur ist so organisiert, dass sie im Rahmen einer Micro-Service-Architektur in der Praxis umgesetzt werden kann und orientiert sich an meinem persönlichen Vorgehen.
Je nach praktischer Implementierung ermöglichen die Komponenten die Erfüllung von Governance-, Qualitäts- und Compliance-Anforderungen, wie sie z. B. an Hochrisiko- oder stark regulierte KI-Systeme und Anwendungen nach EU AI Act gestellt werden.
Letztes Update am 01.11.2025
Inhalt und Aufbau des Artikels
In diesem Artikel möchte ich auf folgende Punkte eingehen:
- Die Komponenten eines vertrauenswürdigen KI-Systems
- Die Frontend-Komponente
- Die Interface-Komponente
- Die Access-Management-Komponente
- Die Anwendungslogik-Komponente
- Die AI-Gateway-Komponente
- Die AI-Security-Komponente
- Die KI-Modell-Komponente (hier ist das eigentliche KI-Modell z. B. ein LLM verortet)
- Die Vektor-DB-Komponente (optional)
- Die Daten-Komponente
- Die Datenverarbeitungs-Komponente
- Die Artefaktverwaltungs-Komponente
- Die Monitoring-Komponente
- Die Observability-, Tracing- & Evaluations-Komponente
- Die Hardware- & Infrastruktur-Komponente
- Die CI/CD- & MLOps-Pipeline-Komponente
- Die Sandbox-Komponente
- Fazit
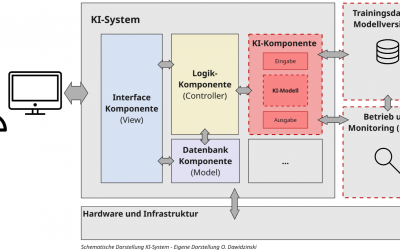
Die Komponenten eines vertrauenswürdigen KI-Systems
In der Praxis gibt es eine Vielzahl von Architektur- und Design-Patterns für Machine-Learning- oder KI-Systeme. Aus meiner Sicht besteht ein (vertrauenswürdiges) KI-System aus mindestens 16 Komponenten oder Bausteinen, die jeweils einen eigenen Funktionsbereich eines KI-Systems abdecken.
Dabei versuche ich, mit den Komponenten eine möglichst universelle Architektur zu beschreiben, die sowohl für generative als auch prädiktive KI-Systeme anwendbar ist und möglichst viele Anwendungsfälle ermöglicht. Je nach Use Case oder Implementierung kann es jedoch vorkommen, dass nicht alle Komponenten zwingend eigenständig benötigt werden (z. B. wäre die Vektor-DB-Komponente außerhalb von RAG-Anwendungen in der Regel nicht notwendig oder könnte als Teil einer Datenbank in der Daten-Komponente geführt werden). Genauso können weitere dedizierte Komponenten notwendig sein.
Bei den 16 Komponenten handelt es sich um folgende:
- Die Frontend-Komponente
- Die Interface-Komponente
- Die Access-Management-Komponente
- Die Anwendungslogik-Komponente
- Die AI-Gateway-Komponente
- Die AI-Security-Komponente
- Die KI-Modell-Komponente (hier ist das eigentliche KI-Modell z. B. ein LLM verortet)
- Die Vektor-DB-Komponente (optional)
- Die Daten-Komponente
- Die Datenverarbeitungs-Komponente
- Die Artefaktverwaltungs-Komponente
- Die Monitoring-Komponente
- Die Observability-, Tracing- & Evaluations-Komponente
- Die Hardware- & Infrastruktur-Komponente
- Die CI/CD- & MLOps-Pipeline-Komponente
- Die Sandbox-Komponente

Im Folgenden werde ich nun auf jede Komponente sowie deren Bedeutung im Rahmen eines vertrauenswürdigen KI-Systems einzeln eingehen:
1 – Die Frontend-Komponente

Beginnen wir mit der Komponente, mit welcher wir als Nutzer von oben erwähnten KI-Tools in der Regel den meisten Kontakt haben: dem Frontend. Das Frontend ist die Benutzeroberfläche (UI), über die Endanwender oder andere Systeme (z. B. im Rahmen von Browser-Automatisierungen). mit dem KI-System interagieren. Es kann eine Webanwendung, eine mobile App, ein Chat-Interface oder auch eine rein programmatische Schnittstelle für andere Software sein. Seine Hauptaufgabe ist es, Eingaben entgegenzunehmen und die Ausgaben des KI-Modells verständlich und nutzbar darzustellen. Wenn wir ChatGPT über den Browser oder die Smartphone-App öffnen, interagieren wir mit dem Frontend. Dieses sollte eine gute User Experience bieten (einfach und intuitiv zu bedienen sein), da dieses häufig den ersten Eindruck für einen Nutzer ausmacht und darüber entscheidet, ob die Anwendung genutzt wird oder nicht.
Ein gut gestaltetes Frontend ist darüber hinaus ein zentraler Hebel für Vertrauen und Sicherheit, denn es ist die direkte Schnittstelle zum Nutzer. Seine Relevanz für vertrauenswürdige KI liegt dabei insbesondere in:
Transparenz und Erklärbarkeit (Explainability): Das Frontend kann genutzt werden, um nicht nur das Ergebnis, sondern auch die Unsicherheit der Vorhersage, die zugrunde liegende Logik (z.B. durch Hervorhebungen in Texten) oder die Grenzen des Systems zu kommunizieren. Dies schafft Vertrauen und setzt die Erklärbarkeit des Modells in eine für den Nutzer verständliche Form um (vgl. Explainable AI)
Menschliche Aufsicht (Human-in-the-Loop) und Incident-Management: Das Frontend kann Schnittstellen implementieren oder bereitstellen, um kritische Entscheidungen sowie Ausgaben durch einen Menschen bestätigen zu lassen oder Feedback des Nutzers (richtig/falsch) für kontinuierliche Verbesserungen zu sammeln. Ein typisches Beispiel wäre die Bestätigung, ob eine von der KI generierte Antwort korrekt ist.
Sichere Dateneingabe: Das Frontend kann erste Client-seitige Validierungen durchführen, um fehlerhafte oder bösartige Eingaben frühzeitig abzufangen. Ein wichtiger Punkt, um sogenannte Prompt-Injektions oder Manipulationen herauszufiltern oder die Eingabeoptionen zu beschränken.
Barrierefreiheit und Fairness: Ein barrierefreies Design stellt sicher, dass das KI-System von einer möglichst breiten Nutzergruppe ohne Diskriminierung verwendet werden kann. Eine Anforderung, welche gerne übersehen wird, aber z. B. im Barrierefreiheitsstärkungsgesetz (BFSG) bereits gesetzlich vorgeschrieben ist.
2 – Die Interface (API)-Komponente

Das Interface (API-Gateway) ist der zentrale „Zugangspunkt“ und die Schnittstelle für alle externen Anfragen an das KI-System. Es fungiert als Vermittler (Zwischenschicht), der Anfragen entgegennimmt, weiterleitet und die Antworten der dahinterliegenden Anwendungslogik zurück an den Client (Aufrufer) sendet. Insbesondere bei Web-Anwendungen findet man häufig eine Trennung von Frontend und Interface, um mit einem dahinterliegenden System zu kommunizieren. Die Trennung bietet die Möglichkeit und Flexibilität, über mehrere Wege auf das KI-System zuzugreifen. So kann bei standardisierten APIs z. B. ein Frontend beliebig ausgetauscht werden, ohne die Schnittstellen zum System ändern zu müssen. Genauso können auf diesem Weg Funktionen eines KI-Systems in andere Anwendungen oder Frontends integriert werden. Ein gutes Beispiel ist wieder OpenAI, das es Endnutzern erlaubt, über ChatGPT (Frontend) mit ihren KI-Modellen und Systemen zu interagieren, aber gleichzeitig Entwicklern die Möglichkeit bietet, die Funktionen programmatisch über ihre Modell-APIs in eigene Anwendungen zu integrieren.
Diese Komponente ist jedoch auch für ein vertrauenswürdiges KI-System unerlässlich, da sie darüber hinaus eine weitere Sicherheits- und Logging-Schicht darstellt. Sie ermöglicht die Integration von weiteren Sicherheits- und Kontrollfunktionen. Im Kontext von vertrauenswürdiger KI ist das Gateway z. B. kritisch für:
Sicherheit: Es schützt die dahinterliegenden Dienste vor dem direkten Zugriff aus dem Internet (falls es sich beim KI-System um ein offen zugängliches System handelt) und kann Authentifizierung, Autorisierung, Rate-Limiting (um Missbrauch und Denial-of-Service-Angriffe zu verhindern) und die Verschlüsselung von Daten (HTTPS) durchführen.
Zuverlässigkeit & Stabilität: Häufig implementiert ein API-Gateway auch gleichzeitig die Funktionen eines Load-Balancers, welches sicherstellt, dass das System auch bei hohem Aufkommen stabil bleibt.
Nachvollziehbarkeit: Als zentraler „Einstiegspunkt“ bietet das Interface optimale Möglichkeiten, um Metriken, Logs und Traces für jede Anfrage zu erfassen, was für das Monitoring der Systemintegrität und die Nachverfolgung von Problemen entscheidend ist. Dazu mehr in der Monitoring- und Observability-Komponente.
3 – Die Access-Management-Komponente
(Authentifizierung und Berechtigungsmanagement)

Die Access-Management-Komponente ist die zentrale technische Einheit für das Identitäts- und Berechtigungsmanagement in einem KI-System. Sie kombiniert zwei kritische und wichtige Funktionen: Die Authentifizierung (Verifizierung der Identität eines Nutzers oder Services) und Autorisierung (Festlegung der erlaubten Aktionen und Ressourcen für diese identifizierte Entität). Eine eigenständige Access-Management-Komponente ist insbesondere in Micro-Service Architekturen häufig zu finden (welche im Grunde mit meiner Komponentenübersicht umgesetzt werden könnte), um ein zentrales Zugangsmanagement zu haben. Andernfalls müsste ggf. für jede einzelne Komponente ein eigenes Zugangs- und Berechtigungsmanagement implementiert werden.
Dies beschreibt auch schon die Relevant im Kontext von vertrauenswürdiger und verantwortungsvoller KI. Die Komponente ist das Rückgrat für Sicherheit, Governance und Compliance. Sie ist unverzichtbar, da über diese der gesamte Zugang geschützt und Audits (Nachvollziehbarkeit der Loggings und Zugriffe) möglich werden.
4 – Die Anwendungslogik-Komponente
(Programmlogik oder Workflows der eigentlichen KI-Anwendung)

Bei der Anwendungslogik handelt es sich um die Komponente, welche die spezifischen Geschäftsprozesse und -regeln umsetzt, welche die KI-Funktionalität in einen nutzbaren Gesamtwert verwandelt. So kann der Zweck eines KI-Systems z. B. sein, den Auftragseingangsprozess in einer Vertriebsabteilung zu (teil-) automatisieren. Innerhalb der Anwendungslogik würde dann programmatisch definiert werden, wie, in welcher Reihenfolge und unter welchen Bedingungen die KI-System-Komponenten (wie Modelle und Datenquellen) miteinander und mit anderen Systemteilen interagieren müssen, um eine konkrete Geschäftsanforderung (in dem Fall die Automatisierung des Auftragseingangsprozesses) zu erfüllen. Sie bildet damit die „Logik“ der KI-Anwendung.
Wenn sich für die Lösung der Problemstellung z. B. für den Einsatz von autonomen KI-Agenten entschieden wird, würde die Anwendungslogik z. B. den Code oder die Workflows für die Agenten-Orchestrierung beinhalten. Wenn im ein Nutzer im Frontend eine Ausgabe als Fehlerhaft bewertet und eine neue Antwort anfordert, dann würde dieses Feedback in der Regel ebenfalls in der Anwendungslogik verarbeitet werden.
Am Agentenbeispiel kann man bereits abschätzen, dass die Anwendungslogik im Rahmen von vertrauenswürdigen KI-Systemen wieder eine kritische Rolle einnimmt, denn die Komponente ist entscheidend, um „KI“ in einen zuverlässigen, sicheren und geschäftsrelevanten Prozess einzubetten. Ihre Relevanz für vertrauenswürdige KI umfasst dabei insbesondere:
Kontextintegration & Geschäftslogik: Die Anwendungslogik kombiniert die Modellein- sowie -ausgaben mit anderen Datenquellen und Geschäftslogik z. B. im Rahmen eines Pre- oder Post-Processing. Häufig müssen Eingaben z. B. zuerst in ein bestimmtes Format transformiert oder auf schädliche Inhalte im Rahmen eines Moderationsprozesses geprüft werden. Beispiel: Ein Kredit-Scoring-Modell gibt einen Score aus; die Anwendungslogik kombiniert diesen mit Bonitätsdaten und firmeninternen Risikoregeln, um eine endgültige Entscheidung (Annahme/Ablehnung) zu treffen. Dies stellt sicher, dass die KI-Entscheidung auf Basis fest definierter Regeln oder Entscheidungskriterien und Prozesse getroffen wird.
Kontrolle (Human-in-the-loop): Die Anwendungslogik ermöglicht Workflows (falls notwendig), bei denen unsichere oder hochriskante Modellentscheidungen zur manuellen Überprüfung an einen menschlichen Experten weitergeleitet werden können (vgl. Beispiel mit fehlerhafter Antwort im Frontend). Dies ist ein zentraler Mechanismus, um Verantwortung sowie Kontrolle sicherzustellen und kritische Fehler zu verhindern.
Robustheit und Fehlerbehandlung: Die Anwendungslogik fängt Fehler und Unsicherheiten des KI-Modells ab und leitet definierte Eskalations- oder Fallback-Strategien ein (z.B.: „Bei niedriger Modellkonfidenz (geringer Vorhersagewahrscheinlichkeit oder Score) manuelle Prüfung auslösen“ oder „Bei Ausfall des Hauptmodells auf ein einfacheres Ersatzmodell umschalten“). Dies macht das Gesamtsystem resilienter.
Nachvollziehbarkeit (Audit Trail): Die Anwendungslogik kann den gesamten Entscheidungspfad einer Anfrage protokollieren – von der Eingabe über die verwendeten Modelle und Daten bis zur finalen Aktion. Dies schafft Transparenz und ist für Compliance und Regulierung unerlässlich.
5 – Die AI-Gateway-Komponente

Beim AI-Gateway (auch LLM Gateway oder Model Gateway) handelt es sich im Grunde um eine spezialisierte Form eines API-Gateways (Schnittstellen-Komponente), das als zentraler Vermittler und Kontrollpunkt zwischen Client-Anwendungen (oder der Anwendungslogik) und einer Vielzahl von KI-Modellen (insbesondere LLMs) dient. Es abstrahiert die Komplexität der verschiedenen zugrunde liegenden Model-Provider (wie OpenAI, Anthropic, Cohere, aber auch eigene bzw. Open Source / Weight- Modelle) und stellt eine einheitliche Schnittstelle bereit. Darüber hinaus ermöglich das AI-Gateway als Knotenpunkt eine zentrale Steuerung und Überwachung von Anfrage- und Ausgaben. Mit Blick auf Governance & Compliance-Anforderungen im Kontext vertrauenswürdiger KI-Systeme macht es das AI-Gateway meiner Meinung nach aus folgenden Gründen zu einer Schlüsselkomponente:
Einheitliche API & Vermeidung von Vendor-Lock-in: Das Gateway entkoppelt die Anwendungslogik von den spezifischen APIs der Model-Anbieter. Dies ermöglicht einen nahtlosen Wechsel zwischen Modellen oder Providern (z.B. von GPT-4 zu Claude 3) ohne Codeänderungen in den konsumierenden Services, was die strategische Flexibilität erhöht.
Zentrale Sicherheits- und Governance-Kontrolle: Als einziger Ausgangspunkt für externe Model-API-Aufrufe kann es eine zentrale Policy-Durchsetzung für Sicherheitsmaßnahmen wie Rate Limiting, Kostenkontrolle (Budgeting), Token-Nutzungs-Tracking und das Filtern von sensiblen Daten (PII-Redaktion) in Anfragen und Antworten realisieren.
AI-Observability: Das Gateway ist der ideale Punkt, um einheitliche Metriken für alle LLM-Aufrufe zu sammeln – unabhängig vom genutzten Provider. Dazu gehören Latenz, Fehlerraten, Kosten pro Anfrage und Token-Nutzung. Dies schafft vollständige Transparenz über die Nutzung und Performance.
Resilienz und Load Balancing: Das Gateway ermöglicht ein flexibles und „intelligentes“ Routing, z.B. automatisches Failover zu einem Fallback-Modell, wenn das primäre Modell ausfällt oder eine Anfrage aufgrund von Quotas (Anfragelimits) ablehnt. Es kann Lasten auch auf mehrere Modelle oder Provider verteilen.
6 – Die AI-Security-Komponente
(Guardrails, Moderation, Filter)

Die AI-Security-Komponente (häufig auch bekannt als Guardrails-, Moderation- oder Filterlayer) ist eine proaktive Sicherheitsschicht, welche insbesondere im Kontext von generativer KI essentiell wichtig ist, um die Ein- und Ausgaben eines KI-Systems in Echtzeit zu überwachen, zu filtern und zu steuern. Sie setzt feste Regeln und Richtlinien durch, um unerwünschtes, schädliches oder unsicheres Verhalten eines (generativen) KI-Modells zu verhindern.
Diese Komponente ist im Kontext von vertrauenswürdigen und verantwortungsvollen KI-Systemen (insbesondere in der Interaktion mit Menschen) absolut kritisch, um die inhärenten Risiken von KI-Modellen, insbesondere LLMs, zu adressieren und operationale Sicherheit zu gewährleisten. Ihre Relevanz für vertrauenswürdige KI umfasst dabei:
Verhinderung von schädlichen Ausgaben: Sie ermöglicht die Blockierung von inhärent unsicheren, unethischen oder illegalen Inhalten, wie z.B. Hassrede, Diskriminierung, gefährliche Anleitungen, Lügen/Halluzinationen, die als Fakten ausgegeben werden, oder die Offenlegung von sensiblen Informationen (Prompt Injection).
Daten- und Prompt-Sicherheit: Sie schützt das Modell vor bösartigen Eingaben (Jailbreak-Prompts, Prompt-Injection-Angriffe), die darauf abzielen, die Sicherheitsvorkehrungen des Modells zu umgehen. Zudem kann sie automatisch persönliche Daten (PII) in Eingaben schwärzen, um Datenschutzverletzungen zu verhindern.
Sicherstellung von Themen-Treue (Thematic Guardrails): Sie hält die KI in einem definierten fachlichen Rahmen und verhindert, dass sie über nicht-autorisierte Themen spricht oder Aktionen außerhalb ihres Verwendungszwecks vorschlägt. Dies ist entscheidend für die Geschäftssicherheit.
Durchsetzung von Compliance und Reputationsschutz: Indem sie schädliche oder peinliche Ausgaben verhindert, schützt sie die Organisation vor rechtlichen Konsequenzen und Reputationsschäden. Sie stellt sicher, dass die KI-Ausgaben konsistent mit den Unternehmenswerten und -richtlinien sind.
7 – Die KI-Modell-Komponente
(Auswahl, Entwicklung/Anpassung und Bereitstellung)

Nun kommen wir zu der Komponente, die im Kern aus einem Software-System ein KI-System macht. Die KI-Modell-Komponente beinhaltet die eigentlichen Modelle oder Algorithmen, die im Rahmen des Systems eine „intelligente“ Prognose, Vorhersage oder andere Funktion/Ausgabe überhaupt ermöglichen. Dabei kann es sich sowohl um „klassische“, prädiktive Machine-Learning-Modelle (ML) handeln als auch um generative (Foundation)-Modelle wie LLMs und Co. Je nach Modell und Anpassung umfasst die KI-Modell-Komponente den gesamten Lebenszyklus des KI-Modells selbst – von der Auswahl des geeigneten Modelltyps oder Algorithmus über dessen Entwicklung/Training, Feinabstimmung (Fine-Tuning) und Validierung bis hin zur finalen Bereitstellung (Deployment) in einer Laufzeitumgebung.
Auch wenn das KI-Modell nur „eine“ Komponente innerhalb des Systems ist, handelt es sich um das Herzstück, den Motor eines jeden KI-Systems, was eine vertrauenswürdige Ausgestaltung unverhandelbar macht. Sie ist direkt mit fast allen Prinzipien vertrauenswürdiger KI verknüpft:
Fairness & Bias-Vermeidung: Die Auswahl der Trainingsdaten, die Modellarchitektur und die Metriken zur Bewertung müssen so gestaltet sein, dass sie unfaire Verzerrungen erkennen und minimieren. Ein voreingenommenes Modell ist ein fundamentales Sicherheits-, Qualitäts- und Reputationsrisiko.
Robustheit & Sicherheit: Insbesondere generative KI-Modelle müssen gegen adversariale Angriffe (gezielte Manipulation der Eingabe zur Täuschung des Modells) und Data- sowie Konzept-Drifts (Änderungen in den Eingabedaten über die Zeit) resilient sein. Dies erfordert spezielle Techniken während des Trainings (z.B. adversarial Training) und ein robustes Design.
Transparenz & Erklärbarkeit (Explainability): Die Wahl zwischen einem komplexen, nicht interpretierbaren „Black-Box“-Modell und einem einfacheren, erklärbaren Modell ist eine zentrale Entscheidung. In regulierten Bereichen ist die Fähigkeit, eine Entscheidung nachvollziehbar zu begründen, oft entscheidend für die Akzeptanz.
Zuverlässigkeit & Performance: Die Komponente muss sicherstellen, dass das Modell die geforderte Genauigkeit und Leistung konsistent erbringt. Dies wird durch rigoroses Testen, Validierung auf ungesehenen Daten (Trainings-, Test- und Evaluationsdaten -> vgl. Data-Komponente) und Leistungsbenchmarks vor dem Deployment gewährleistet.
8 – Die Vektor-DB-Komponente
(Optional)

Die Vektor-Datenbank (Vector Database) ist eine Besonderheit und grundsätzlich nicht für jedes KI-System relevant. Da jedoch insbesondere im Kontext von generativen KI-Anwendungen viele Use Cases sogenanntes Information Retrieval (IR) erfordern, um Halluzinationen und fehlendem Wissen zu begegnen, führe ich diese als eigene Komponenten. Bei einer Vektor-Datenbank handelt es sich vereinfacht gesagt um eine spezialisierte Art von Datenbank, die darauf optimiert ist, hochdimensionale Vektoren (numerische Repräsentationen von Daten, z.B. Text, Bilder, Audio) effizient zu speichern, zu indizieren und abzufragen. Ihr Hauptzweck ist die schnelle Suche nach den „ähnlichsten“ Vektoren zu einem gegebenen Suchvektor, basierend auf mathematischen Abstandsmaßen.
Wie bereits erwähnt, spielt die Komponente insbesondere im Kontext von IR-Anwendungsfällen im Bereich der Large Language Models (LLMs) eine große Rolle und ist eine Kernkomponente von sogenannten Retrieval Augmented Generation (RAG) Anwendungen. Ihre Relevanz für vertrauenswürdige KI liegt dabei in:
Faktenbasierte Wissensanreicherung (RAG): Sie ermöglicht Retrieval-Augmented Generation (RAG), bei der relevantes, unternehmenseigenes Wissen aus der Vektor-DB abgerufen und dem LLM als Kontext bereitgestellt wird. Dies ist die effektivste (wenn auch nicht 100%ig sichere) Methode, um Halluzinationen zu reduzieren und die Antworten des LLMs auf faktenbasierte, überprüfbare Informationen zu gründen – ein entscheidender Faktor für Vertrauen und Genauigkeit.
Konsistenz und Nachvollziehbarkeit: Im Gegensatz zum reinen Gedächtnis eines LLMs, das undurchsichtig und variabel sein kann, bietet die Vektor-DB eine konsistente, versionierbare und überprüfbare Wissensquelle. Man kann genau nachweisen, welche Informationen für eine bestimmte Antwort herangezogen wurden, was die Nachvollziehbarkeit und Audit-Fähigkeit dramatisch erhöht.
Aktualität und Kontrolle: Das Wissen eines statischen (vortrainierten) LLMs ist auf die verwendeten Trainingsdaten beschränkt und damit oft „veraltet“ und nicht ohne Probleme austauschbar. Die Vektor-DB hingegen kann dynamisch mit aktuellen Unternehmensdokumenten, Prozesshandbüchern oder Support-Artikeln aktualisiert werden. Dies gibt Firmen, Organisationen oder allgemein Nutzern die volle Kontrolle über das Wissen, das die KI-Modelle verwenden, und stellt deren Relevanz und Richtigkeit (meistens) sicher.
Datenhoheit und Sicherheit: Anstatt sensibles Unternehmenswissen an externe LLM-APIs zu senden (was Datenschutzprobleme aufwerfen kann), können die Vektor-Embeddings lokal oder in der eigenen Cloud oder Betriebsumgebung gehalten werden. Nur die relevantesten Textstücke werden bei Bedarf ausgelesen und im Prompt verwendet, was die Datenexposition minimiert.
9 – Die Daten-Komponente
(DB, Drittsysteme etc.)

Kommen wir zur Datenkomponente. Vor der Zeit der generativen KI-Modelle waren Daten und damit die Datenhaltung untrennbar mit einem KI-Modell verbunden, da diese für das Training und damit die Erstellung eines KI-Modells zwingend erforderlich waren. Mit Foundation-Models wie LLMs ist die Notwendigkeit von eigenen Daten in der Regel auf ein sogenanntes Fine-Tuning beschränkt.
Doch auch abseits des KI-Modells ist die Datenhaltung für ein KI-System eine zwingende Komponente. Diese umfasst die Gesamtheit aller Datenspeicher und -quellen, die für den Betrieb des KI-Systems notwendig sind. Dies schließt strukturierte Datenbanken (SQL/NoSQL), Data Warehouses, Data Lakes, Streaming-Plattformen, Dateisysteme sowie Schnittstellen zu externen Drittsystemen (z.B. CRM, ERP) ein. So muss jede Komponente in irgendeiner Form Daten ablegen oder auf solche zugreifen. Sie ist die fundamentale Wissensbasis des Systems.
Im Rahmen einer Microservice-Architektur kann man sich die Datenkomponente als die zentrale Datenverwaltung und -haltung vorstellen, in der komponentenübergreifend alle Informationen gespeichert werden.
Für vertrauenswürdige KI-Systeme hat die Datenkomponente damit eine herausragende Bedeutung. Ihre Qualität, Integrität und Sicherheit bestimmen maßgeblich die Vertrauenswürdigkeit des gesamten KI-Systems.
Datenqualität & Fairness: Die Qualität der Trainings- oder Produktionsdaten bestimmt direkt die Qualität und Fairness des KI-Modells bzw. seiner Ausgaben. Hier gilt uneingeschränkt „Garbage in, garbage out“. Schlechte, verzerrte oder unvollständige Daten führen zu unzuverlässigen und voreingenommenen Modellen. Eine robuste und konsistente Datenhaltung ermöglicht Data Profiling, Bereinigung und Validierung (z. B. in Komponente 10 – Datenverarbeitung), wodurch die Qualität sichergestellt werden kann.
Datenherkunft & Nachvollziehbarkeit: Für Audits, Fehleranalysen und Regulierungskonformität (z.B. gemäß DSGVO „Right to Explanation“), aber auch für die Entwicklung selbst, muss lückenlos nachvollziehbar sein, aus welchen Quellen die Daten stammen. Häufig werden Daten aus unterschiedlichen Anwendungen oder sogenannten Datensilos benötigt. So kann die Datenkomponente z. B. mehrere unterschiedliche Datenbanken oder Drittsysteme umfassen, aus denen das KI-System Daten bezieht oder in die es schreibt. Innerhalb der Datenkomponente kann dies zentral nachvollzogen und dokumentiert werden.
Datensicherheit & Zugriffskontrolle: Da alle KI-System-Komponenten in der Regel Daten speichern oder lesen, muss der Zugriff darauf, z. B. durch granulare Zugriffskontrollen, abgesichert werden. Dies dient dem Schutz sensibler Daten (PII, Geschäftsgeheimnisse) vor unbefugtem Zugriff. Innerhalb der Datenkomponente kann dies zentral umgesetzt werden.
Aktualität & Konsistenz: In der Regel müssen die Daten für ein KI-System konsistent und aktuell sein. Über die Datenkomponente können zentrale Mechanismen oder Schnittstellen für Datenaktualisierung und -synchronisation bereitgestellt werden, mit denen die Aktualität und Konsistenz sichergestellt werden kann.
10 – Die Datenverarbeitungs-Komponente
(Datenverwaltung, Transformation und Bereitstellung)

Wo die Datenkomponente sich auf die Datenbereitstellung und -verwaltung fokussiert (z. B. eine Datenbank und deren Schnittstellen), umfasst die Datenverarbeitungs-Komponente die Prozesse und Logiken für die Verwaltung, Transformation und Bereitstellung von Daten innerhalb des KI-Systems. Sie umfasst alle Prozesse und Pipelines, die Rohdaten aus den Quellsystemen (Datenbanken, Drittsysteme etc.) erfassen, bereinigen, validieren, anreichern oder in ein geeignetes Format transformieren, um diese schließlich der KI-Modell-Komponente oder der Anwendungslogik bereitstellen.
In der Regel handelt es sich dabei um ETL- (Extract-Transform-Load) / ELT- (Extract-Load-Transform) Pipelines, welche z. B. aus der Menge an möglichen Datenquellen innerhalb der Datenkomponente nur die Daten laden, die für den Anwendungsfall im KI-System gebraucht werden.
Mit Blick auf vertrauenswürdige KI ist die Datenverarbeitungskomponente insbesondere im Kontext von Datenqualität und Reproduzierbarkeit wichtig. Ihre Relevanz umfasst dabei insbesondere:
Gewährleistung von Datenqualität und Konsistenz: Sie ermöglicht die Automatisierung kritischer Schritte wie die Bereinigung von Ausreißern, die Handhabung fehlender Werte, Normalisierung oder die Validierung der Daten gegen bestimmte Geschäftsregeln oder Sicherheitskriterien. Nur konsistente, hochwertige Daten führen zu zuverlässigen und fairen (qualitativ hochwertigen) Prognosen, Vorhersagen oder allgemein Ausgaben.
Reproduzierbarkeit: Durch Versionierung der Daten (dazu in der Komponente 11 – Artefakt-Verwaltung) und der Transformationspipelines (z.B. mit Git) stellt die Datenverarbeitungskomponente sicher, dass Modelle, Prognosen oder Workflows mit den gleichen Verarbeitungsschritten und Daten reproduziert werden können. Dies ist insbesondere für Audits, Debugging und Compliance unerlässlich.
Bekämpfung von Bias: Transformationsschritte können genutzt werden, um gezielt Verzerrungen in den Daten entgegenzuwirken, z.B. durch gezieltes Unter- bzw. Übersampling unterrepräsentierter Gruppen. Dadurch können Anforderungen an Bias-Freiheit oder Fairness erfüllt werden.
Datensicherheit: In Datenbanken befinden sich häufig sensible oder personenbezogene Daten, die vom KI-System nicht einfach verändert werden dürfen. Im Rahmen von ETL-Pipelines erlaubt die Datenverarbeitungskomponente, solche Daten zu anonymisieren oder zu pseudonymisieren, bevor sie vom KI-Modell oder in anderen Komponenten verarbeitet werden.
11 – Die Artefaktverwaltungs-Komponente

In der Datenverarbeitungs-Komponente wurde bereits der Punkt Reproduzierbarkeit durch z. B. Versionierung angesprochen. Dies ist im Kern die Aufgabe der Artefaktverwaltungskomponente. Die Artefaktverwaltung ist ein zentrales System zur Versionierung, Speicherung und Verwaltung aller während des ML- oder KI-Lebenszyklus generierten Objekte (sogenannte Artefakte). Dazu gehören in erster Linie die KI-Modelle (z.B. serialisierte ML-Modelle oder LLM-Versionen nach dem Fine-Tuning), aber auch Datenversionen (z. B. genutzte Datensätze oder Features), verschiedene Prompts, Trainingsskripte, Konfigurationsdateien, Vorverarbeitungspipelines und Evaluierungsergebnisse.
Die Artefaktverwaltung ist während des gesamten Lebenszyklus des KI-Systems von zentraler Bedeutung, da sie, wie angesprochen, die Reproduzierbarkeit, Nachvollziehbarkeit sowie gegebenenfalls Rollbacks ermöglicht. Dies macht sie ebenfalls zu einer Kernkomponente eines vertrauenswürdigen und verantwortungsvollen KI-Systems. So adressiert die Komponente im Kern die folgenden Punkte:
Reproduzierbarkeit & Auditierbarkeit: Die Artefaktverwaltung ermöglicht es, jedes jemals in Produktion gebrachte Modell, jede Pipeline oder jeden Workflow exakt nachzubilden. Im Falle von Fehlverhalten, Regulierungsanfragen oder Audits kann so lückenlos nachgewiesen werden, welches Modell mit welchen Daten und Konfigurationen (z. B. verschiedene System-Prompts) wann verwendet wurde.
Rollbacks & Stabilität: Bei Leistungsabfall (Model- oder Concept-Drift) oder unerwartetem Verhalten nach einer Anpassung kann durch die Versionierung schnell und sicher auf eine frühere, stabile Modell- oder Konfigurationsversion zurückgesetzt werden. Aus Erfahrung kann ich sagen, dass dies eine absolute Notwendigkeit ist.
Nach- und Rückverfolgbarkeit: Die Artefaktverwaltung stellt sicher, dass die vollständige Historie – von den Trainingsdaten über den Code bis zum spezifischen Modell-Artefakt – nachverfolgt werden kann. Dies ist kritisch, um z. B. Fragen zur Fairness oder zu Bias zu beantworten (z. B.: „Auf Basis welcher Datensatzversion wurde dieses ‚unfaire‘ Modell trainiert?“).
Kollaboration & Governance: Sie bietet eine kontrollierte Umgebung, in der Entwickler, Data Scientists oder Auditoren arbeiten und ihre Artefakte freigeben können, ohne dass diese verloren gehen oder unkontrolliert dupliziert werden. Der Zugriff kann z. B. über die Access-Management-Komponente gesteuert werden.
12 – Monitoring-Komponente

Kommen wir zum Monitoring. Die vorangegangenen Komponenten erfüllen im Grunde alle funktionalen Ziele des KI-Systems. Die Aufgabe des Monitorings ist es nun, sicherzustellen, dass die einzelnen Komponenten sowohl in der Entwicklung als auch im Betrieb ebenfalls ihre nicht-funktionalen Ziele und Anforderungen einhalten. Die Monitoring-Komponente ist das reaktive Frühwarnsystem des KI-Systems. Sie ist für die kontinuierliche Überwachung vordefinierter technischer und geschäftlicher Metriken zuständig, vergleicht diese gegebenenfalls mit Schwellenwerten und löst Alarme aus, wenn diese Werte überschritten werden.
Das Monitoring ist die grundlegende Überwachungsebene, die beim Über- oder Unterschreiten von festgelegten Metriken oder Kriterien Alarm schlägt (z. B. Genauigkeit, Geschwindigkeit, Vertrauenswürdigkeit etc.). Sie arbeitet damit Hand in Hand mit der Observability-Komponente, welche noch tiefergehende Analysen ermöglicht (dazu gleich mehr in der Komponente 13 – Observability, Tracing & Evaluation).
Für ein vertrauenswürdiges System ist sie unverzichtbar, weil sie:
Betriebsbereitschaft und Stabilität sicherstellt: Sie überwacht die technischen Parameter (CPU, RAM, Latenz, Fehlerraten, Durchsatz) der einzelnen Komponenten oder Services. Dies gewährleistet, dass das KI-System überhaupt verfügbar und performant ist.
Daten- und Modell-Drift erkennt: Sie kann Alarme auslösen, wenn vordefinierte Drift- oder Qualitätsmetriken einen kritischen Schwellenwert überschreiten. Dies ermöglicht die proaktive Information von Verantwortlichen, dass die Modell- oder Systemleistung nachlässt und z. B. ein Retraining oder eine Untersuchung notwendig ist.
Ressourcennutzung und Kosten kontrolliert: Besonders im Kontext von generativer KI und ressourcenhungrigen LLMs ist das Monitoring von z. B. Token-Verbrauch, API-Kosten oder Ressourcenauslastung entscheidend, um unerwartete Kostenexplosionen zu verhindern.
Sicherheitsvorfälle meldet: Ein ungewöhnlicher Anstieg der Anfragezahlen (möglicher Denial-of-Service-Angriff) oder Zugriffsversuche von unbekannten Quellen können durch Monitoring erkannt und gemeldet werden.
13 – Observability-, Tracing- & Evaluations-Komponente

Wo die Monitoring-Komponente „bekannte“ Risiken adressiert (um zu tracken, ob die Performance eines KI-Modells nachlässt, muss vorher bekannt sein, was der Soll-Wert bzw. die Baseline ist) und Alarm schlägt, falls es zu Abweichungen oder Problemen kommt, konzentriert sich die Observability- und Tracing-Komponente darauf, die Ursachen und Gründe zu ermitteln.
Bei der Observability-, Tracing- & Evaluation-Komponente handelt es sich um die proaktive „Wahrnehmungs- und Analyse-Einheit“ des KI-Systems. Sie geht weit über das reaktive Monitoring (Alarme bei Schwellwertüber- oder -unterschreitungen) hinaus und zielt darauf ab, den internen Zustand und die Qualität des Systems durch die Analyse von externen Daten (z. B. Logs) zu verstehen. Dazu sammelt sie Metriken, Logs und Traces über alle Komponenten und Prozessschritte hinweg, um die Ursachen für mögliche Probleme, Schwellwertüberschreitungen oder Ausgaben nachvollziehen und verstehen zu können.
So gut man ein (generatives) KI-System im Vorfeld auch plant: In der Produktion ist es eher die Regel als die Ausnahme, dass sich die Qualität der Ausgaben oder interne sowie externe Parameter ändern. Sei es durch sich ändernde Daten, neue Gefahren oder unbekannte Situationen / Bugs. Die Observability- und Tracing-Komponente ermöglicht es, dieser Dynamik im Betrieb zu begegnen und proaktiv prüfen zu können, ob es potenziell zu Abweichungen kommen kann oder was die Ursache für bereits eingetretene Situationen ist. Man spricht dabei häufig auch von MLOps, also der Überwachung von ML- und KI-Modellen und Systemen im Betrieb, wozu auch die Monitoring-Komponente gehört.
Mit Blick auf den zunehmenden Einsatz von (autonomen) KI-Agenten ist die Observability- und Tracing-Komponente eine absolute Notwendigkeit, um z. B. die Handlungen und Entscheidungen der Agenten verfolgen und nachvollziehen zu können.
Im Kontext von vertrauenswürdiger KI machen insbesondere die folgenden Möglichkeiten eine Observability-, Tracing- und Evaluations-Komponente unabdingbar:
Früherkennung von Modellverschlechterung (Drift): Sie ermöglicht es zu erkennen, wenn sich die Eingabedaten (Data Drift) oder die statistische Beziehung zwischen Ein- und Ausgabe (Concept Drift) ändern, was die Modellgenauigkeit untergräbt. Dies geschieht, bevor es zu Ausfällen im Betrieb kommt.
Ursachenanalyse bei Fehlern (Root Cause Analysis): Wenn eine Vorhersage/Ausgabe falsch oder unerwartet ist, erlaubt z. B. das Distributed Tracing, den Request lückenlos durch alle Komponenten oder Services (Datenbank, Feature-Store, Modell, etc.) zu verfolgen. So lässt sich isolieren, ob das Modell, die Datenvorverarbeitung oder eine andere Komponente die Ursache war.
Quantifizierung von Vertrauenswürdigkeit: Sie ermöglicht die „Übersetzung“ abstrakter Konzepte wie „Fairness“ und „Stabilität“ in messbare Metriken (z.B. Unterschiede in Genauigkeit zwischen Nutzergruppen, Varianz der Vorhersagen) sowie deren kontinuierliche Überwachung.
Transparenz und Nachvollziehbarkeit (Auditability): Sie protokolliert nicht nur, dass etwas schiefgelaufen ist, sondern schafft durch Tracing und Evaluation den Kontext, warum es schiefgelaufen ist. Dies ist für Compliance und Regulierung unerlässlich.
14 – Hardware & Infrastruktur Komponente

:Bislang wurde nur über die reinen Software-Komponenten eines KI-Systems gesprochen. Diese müssen jedoch auch auf einer Infrastruktur aufsetzen. Die Hardware- & Infrastruktur-Komponente bildet diese physische und virtualisierte Grundlage, auf der alle anderen Komponenten des KI-Systems laufen. Sie umfasst die gesamte Rechenleistung (CPUs, GPUs etc.), Speichersysteme, Netzwerkinfrastruktur sowie die Verwaltungsebene (z.B. Virtualisierung, Container-Orchestrierung), die Ressourcen bereitstellt, skaliert und verwaltet.
Während sich die Diskussion um verantwortungsvolle KI oft nur auf die KI-Modelle und Daten konzentriert, ist die zugrundeliegende Hardware und Infrastruktur mindestens gleichbedeutend, da diese das Fundament bildet, welches Sicherheit, Datenschutz und Kontrolle überhaupt erst ermöglicht. Darüber hinaus spielt die Hardware- und Infrastruktur eine entscheidende Rolle bei der Souveränität des KI-Systems und Abhängigkeit von Drittanbietern. Ihre Ausgestaltung wirkt sich damit direkt auf die Vertrauenswürdigkeit und Akzeptanz eines KI-Systems aus:
Gewährleistung von Datenschutz und Sicherheit: Durch die Kontrolle über die Hardware-Infrastruktur können sensible Daten geschützt und datenschutzrechtliche Anforderungen wirksam umgesetzt werden. So können für hochsensible Anwendungsfälle z. B. lokale Rechenzentren oder On-Premise-Lösungen die Verarbeitung sensibler Informationen ohne Abhängigkeit von externen Cloud-Diensten ermöglichen und sicherstellen. Hardwareseitige Verschlüsselungen sowie Maßnahmen zur Sicherheit der Betriebsumgebung sind für viele Use-Cases oder regulatorische Anforderungen Grundvoraussetzung.
Sicherstellung digitaler Souveränität: Die Hardware- und Infrastruktur-Komponente ermöglicht technologische Souveränität und Unabhängigkeit von ausländischen Cloud-Anbietern. Durch die Wahl des Standortes der Rechenzentren können nationale Datenschutzvorschriften wie die DSGVO konsequent eingehalten werden. Diese Kontrolle über die technologische Basis schafft Vertrauen bei Nutzern und Aufsichtsbehörden, da die Einhaltung rechtlicher Rahmenbedingungen direkt gesteuert und nachgewiesen werden kann. Besonders für kritische Anwendungen in Bereichen wie Gesundheitswesen oder öffentlicher Verwaltung ist diese souveräne Infrastruktur unverzichtbar.
Grundlage für Leistung und Zuverlässigkeit: Die hardwaretechnische Ausstattung bestimmt maßgeblich die Performance und Verlässlichkeit des KI-Systems. Insbesondere im Kontext von generativen KI-Systemen braucht es vielfach extrem potente Hardware (GPUs, TPUs etc.), um leistungsfähige LLMs (Large Language Models) zu betreiben und – noch wichtiger – diese auch bei dynamischer Nachfrage performant im Betrieb nutzen und skalieren zu können (geringe Latenzen, hoher Durchsatz, parallele Verarbeitung etc.). Hier spielen insbesondere Container- und Orchestrierungsframeworks eine große Rolle. Zusätzlich muss sichergestellt werden, dass die Systemkomponenten ausfallsicher designed und konzipiert sind, um z. B. bei kritischen Anwendungen einen kontinuierlichen Betrieb zu ermöglichen. Der Punkt ist häufig ein großer Stolperstein bei der Überführung eines Proof-of-Concepts in den Produktionsbetrieb, da z. B. Latenzen nicht berücksichtigt wurden.
Voraussetzung für Nachvollziehbarkeit und Transparenz: Eine kontrollierte Infrastruktur ermöglicht eine umfassende Auditierbarkeit und Transparenz. In der Regel sind alle großen Cloud-Anbieter (egal, ob Public- oder Private-Cloud) bereits hinreichend zertifiziert, jedoch sollte darauf auch aktiv geachtet werden. Die Nachvollziehbarkeit der technischen Umgebung ist vielfach eine grundlegende Voraussetzung für die Zertifizierung und Validierung von KI-Systemen in regulierten Branchen oder für den Betrieb.
Umsetzung ethischer und nachhaltiger KI: Die Hardware-Infrastruktur ermöglicht mit Blick auf zunehmende Nachhaltigkeitsanforderungen zudem die Umsetzung ethischer und ökologischer Prinzipien. Durch gezielte Auswahl energieeffizienter Hardware-Komponenten oder auch kleinerer KI-Modelle sowie die Integration erneuerbarer Energiequellen kann die Umweltbilanz optimiert werden. Direktes Monitoring von Ressourcenverbräuchen schafft Transparenz über die ökologischen Auswirkungen und ermöglicht kontinuierliche Verbesserungen hin zu nachhaltiger KI.
15 – CI/CD & MLOps-Pipeline-Komponente
(Pipelines zum Testen, Bauen und Ausliefern (Deployment) von Code, Modellen (z. B. im Rahmen eines Re-Trainings) und Konfigurationen über die verschiedenen Umgebungen (Dev -> Sandbox -> Staging -> Prod)).

Insbesondere bei der Monitoring- sowie der Observability-, Tracing- und Evaluations-Komponente haben wir davon gesprochen, dass es bei einem KI-System wichtig ist, laufend und rechtzeitig über Fehler oder Probleme informiert zu werden (Monitoring -> WAS funktioniert nicht?) und herausfinden zu können, was die Ursache ist (Observability und Tracing -> WARUM funktioniert es nicht?). Sobald wir beides haben, müssen wir natürlich handeln und das Problem oder die Ursache beheben. Das Gleiche gilt natürlich auch für die planmäßige Weiterentwicklung und Wartung des Systems. Für dieses Vorgehen hat sich in der Software- als auch KI-Systementwicklung die Praxis der kontinuierlichen Integration (CI – Continuous Integration) und der kontinuierlichen Bereitstellung (CD – Continuous Delivery/Deployment) etabliert.
Die CI/CD- & MLOps-Pipeline-Komponente umfasst damit Prozesse, Tools und Workflows, die für die Bereitstellung von Anpassungen sowie deren Überprüfung (Tests) im Betrieb notwendig sind. Sie orchestriert und automatisiert z. B. die Prozesse zum Testen, Bauen, Paketieren und Ausliefern von Code, KI-Modellen und Konfigurationen über verschiedene Umgebungen hinweg (z.B. Dev -> Sandbox -> Staging -> Prod). Über die CI/CD-Komponente wird quasi die kontinuierliche Wartung und Weiterentwicklung zentral und möglichst standardisiert sowie nachvollziehbar organisiert, was sie mit Blick auf ein vertrauenswürdiges KI-System zwar nicht zwingend notwendig macht, aber durch standardisierte und wiederholbare Prozesse einen großen Einfluss auf die Entwicklungsgeschwindigkeit, Qualitätssicherung sowie die operative Stabilität hat:
Gewährleistung von Qualität und Sicherheit: Jede Änderung (Code, Modell, Konfiguration) durchläuft z. B. eine Pipeline mit automatisierten Tests – von Unit-Tests über Integrationstests bis hin zu spezifischen Modelltests (Bias-Checks, Robustheitsvalidierung, Erklärbarkeit). Nur fehlerfreie und sichere Artefakte werden in die nächste Umgebung befördert.
Reproduzierbarkeit und Nachvollziehbarkeit (Audit Trail): Jede in Produktion gebrachte Änderung kann exakt nachvollzogen werden. Die Pipeline protokolliert z. B., welcher Code mit welchen Daten welches Modell-Artefakt erzeugt und ausgeliefert hat. Dies schafft eine lückenlose, revisionssichere Dokumentation für Compliance oder Audits (Forensik).
Schnelle und sichere Reaktion auf Drift: Sie ermöglicht ein automatisches oder manuell getriggertes Retraining von Modellen bei Leistungsverschlechterung (Drift) und liefert das neue Modell sicher und getestet in Produktion aus. Dies erhält die Genauigkeit und Zuverlässigkeit des Systems über die Zeit.
Risikominimierung durch gestaffelte Releases: Durch das schrittweise Ausrollen über Sandbox (dazu gleich in der Komponente 16 – Sandbox mehr), Staging und Produktion können Fehler in einer sicheren Umgebung entdeckt und behoben werden, bevor sie alle Nutzer betreffen.
16 – Sandbox-Komponente
(Entwicklungsumgebung zum sicheren Erproben und Testen einzelner Funktionen. Ggf. digitaler Zwilling)

In der CI/CD-Komponente ging es um die kontrollierte Implementierung und Umsetzung von Bugfixes, neuen Features oder allgemein der Wartung des KI-Systems. Dabei sind bereits Begriffe wie „Dev-Umgebung“, „Staging-Umgebung“ und „Produktionsumgebung“ gefallen. Dabei handelt es sich um einen Mehrstufigen Ansatz, um sicherzustellen, dass es nur Bugfixes oder neue Features in das Produktionssystem (zum Endnutzer) schaffen, welche auch vollumfänglich funktionieren, in dem diese in einer (mehrstufigen) sicheren Umgebung im Vorfeld getestet werden.
Bei der Sandbox-Komponente ermöglicht genau dies. Bei dieser handelt es sich nun im Grunde um eine strikt isolierte und kontrollierte Entwicklungsumgebung, welche es Data Scientists, AI-Engineers und Entwicklern ermöglicht, neue KI-Modelle, Codeänderungen oder Konfigurationen sicher im Vorfeld zu erproben, zu testen und zu validieren, ohne das laufende Produktivsystem zu gefährden. Sie arbeitet damit Hand in Hand mit der vorher vorgestellten CI/CD-Komponente (Komponente 15). Sie kann in der Praxis als einfache Testumgebung ausgestaltet sein oder einen kompletten digitalen Zwilling der Produktion umfassen, der sowohl die Infrastruktur als auch die Datenströme und Schnittstellen simuliert oder kopiert.
Die Sandbox-Komponente ist ein entscheidender Sicherheits- und Qualitätshebel im Lebenszyklus eines KI-Systems. Sie trägt direkt zur Vertrauenswürdigkeit bei, indem sie:
Risikofreie Experimente ermöglicht: Sie schafft einen geschützten Raum für neue Features, in dem auch radikale Ideen und Experimente ohne Angst vor Produktionsausfällen, Datenfehlern oder Sicherheitsverletzungen getestet werden können. Dies ermöglicht in vielen Fällen überhaupt erst eine kontinuierliche Weiterentwicklung des KI-Systems, da es ansonsten häufig einen Zielkonflikt zwischen der Sicherstellung des operativen Betrieb und der Weiterentwicklung gibt, wenn Änderungen nur im Live-System erprobt werden können.
Umfassende Validierung vor dem Produktiveinsatz sicherstellt: In der Sandbox können Integrationstests, Lasttests und Sicherheitstests (z.B. adversariale Angriffe) unter realistischen Bedingungen durchgeführt werden. Dies identifiziert Probleme frühzeitig, bevor sie in die Staging- oder Produktionsumgebung gelangen.
Daten- und Modellsicherheit gewährleistet: Durch strikte Isolation wird verhindert, dass sensible Produktionsdaten in die Entwicklungsumgebung gelangen oder dass nicht validierte, potenziell schädliche Modelle mit echten Systemen interagieren. Der Zugriff kann streng kontrolliert werden.
Realistische Leistungsbewertung erlaubt (als digitaler Zwilling): Ein hochwertiger digitaler Zwilling, der die Produktionslast und -daten simuliert, erlaubt es, die Performance und Skalierbarkeit neuer Modelle genau zu bewerten. So können Engpässe erkannt werden, bevor sie den echten Nutzer treffen.
Fazit
Die vorgestellten Komponenten sind meine persönliche Sicht auf die Konzeption und die notwendigen Bausteine eines vertrauenswürdigen und sicheren KI-Systems. Auch wenn der Aufhänger „vertrauenswürdige KI“ ist, so sind für mich die einzelnen Komponenten gleichzeitig auch aus Qualitätsgründen – unabhängig davon, ob vertrauensvoll oder nicht – absolut notwendig. Ein qualitativ hochwertiges KI-System erfüllt in den meisten Fällen auch die Anforderungen an Vertrauenswürdigkeit.
Dies war meiner Meinung nach vor dem Durchbruch von generativer KI auch grundsätzlich immer eine Selbstverständlichkeit, einfach um sicherzustellen, dass das entwickelte KI-System, oder besser gesagt Modell, auch das erreicht, wofür es entwickelt wurde. Der aktuelle Fokus auf Vertrauenswürdigkeit und Sicherheit liegt meiner Meinung nach darin begründet, dass generative KI-Systeme eben nicht wie „früher“ rein deterministisch und aufgabenspezifisch genutzt werden können. Dies gilt insbesondere mit Blick auf die aktuelle Entwicklung hin zu autonom agierenden KI-Agenten, welche „selbstständig“ Entscheidungen treffen.
Zusätzlich werden die Modelle in den wenigsten Fällen selbst entwickelt oder trainiert, sondern es wird auf fertige Modelle großer Anbieter zurückgegriffen. Dadurch fehlt in vielen Unternehmen oder Verantwortlichen auch schlicht die Expertise zur Bewertung und Absicherung von KI-Systemen. All diese Gründe machen einen deutlich stärkeren Fokus auf eine sicherheitsorientierte und nachvollziehbare Architektur notwendig.
Die vorgeschlagenen Komponenten sollen dabei einen Rahmen und einen Überblick für Interessierte, Berater oder Entwickler von KI-Systemen geben. Die genaue Umsetzung ist dabei immer projekt- und technologieabhängig, jedoch lassen sich die notwendigen Tools, Frameworks oder Services meiner Erfahrung nach gut in dieser Übersicht verorten.
Ich freue mich sehr über jedes Feedback, Verbesserungsvorschläge oder andere Erfahrungen und Vorgehensweisen.
Offenlegung: Bei der Beschreibung einzelner Komponenten sowie der Korrekturprüfung habe ich mich von KI unterstützen lassen.
0 Kommentare